12.2 Estimating IPT weights via modeling
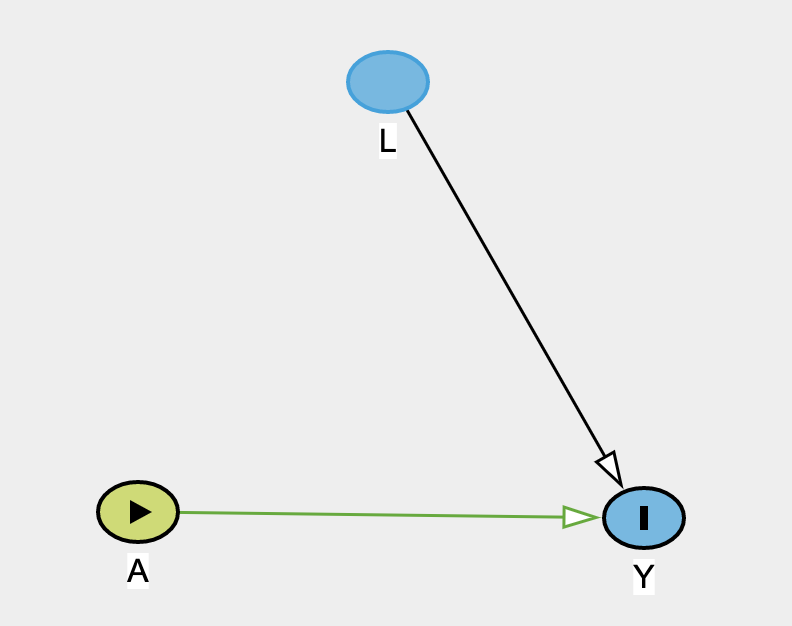
- IPTW ➡️ pseudo-population in which the arrow from L to the treatment A is removed
- \(A \perp\perp\ L\)
- \(E_{ps}[Y|A=a]\) = \(E_l[Y|A=a, L=l]Pr[L=l]\)
- Mean outcome expectation in the IPT-weighted population equals the standardized mean outcome in the initial population
- If \(Y^{a}\perp\perp\ A|L\) holds in the initial population:
- Mean PO \(Y^a\) is the same in initial and IPT-weighted populations
- Marginal (unconditional exchangeability) holds in the IPT-weighted population
- Counterfactual mean \(E[Y^a]\) in the initial population equals observed mean in IPT-weighted population \(E_{ps}[Y|A=a]\)
- In the IPT-weighted population observed associational quantity has a causal interpretation
- Initial population
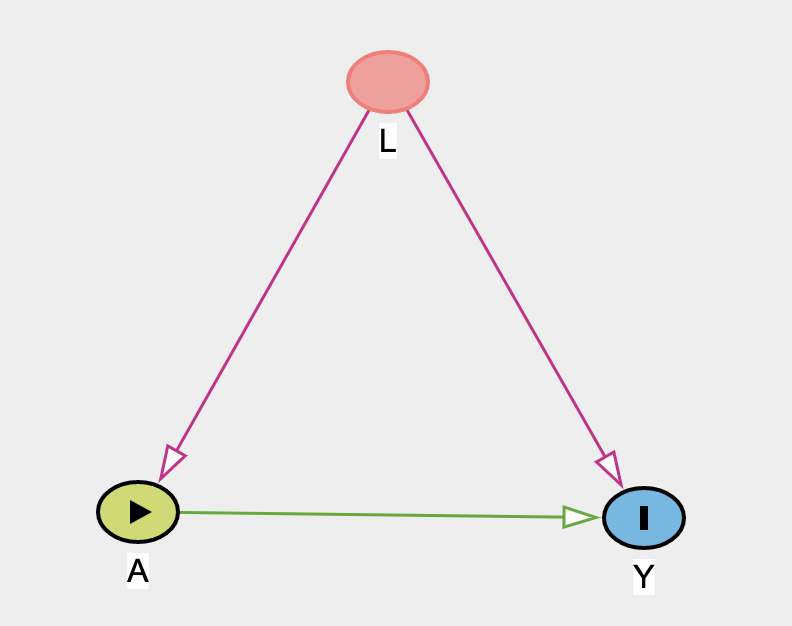
- IPT-weighted population
- Code IPTW
- IPTW distribution code
- IPTW distribution unstab
- IPTW distribution stab
- results code
- 95% CIs bootstrap for stab weights
- 95% CIs bootstrap for unstab weights
pr_a <- glm(data = data, formula = qsmk~1, family = binomial("logit"))pr_a_l <- glm(data = data, formula = qsmk ~ sex + race + age + I(age*age) + education + smokeintensity + I(smokeintensity*smokeintensity) + smokeyrs + I(smokeyrs*smokeyrs) + exercise + active + wt71 + I(wt71*wt71), family = binomial("logit"))data %<>% mutate( p_a = predict(object = pr_a, type = "response"), p_a_l = predict(object = pr_a_l, type = "response"), # for average treatment effect iptw = if_else(qsmk == 1, 1/p_a_l, 1/(1-p_a_l)), # unstabilized weights sw_iptw = if_else(qsmk == 1, p_a/p_a_l, (1-p_a)/(1-p_a_l)) # stabilized weights)p_iptw <- data %>% group_by(qsmk) %>% ggplot(aes(x = iptw, color = qsmk, fill = qsmk)) + geom_histogram(bins = 50) + theme_minimal() + scale_fill_manual(values = wesanderson::wes_palette("GrandBudapest1", n = 2)) + scale_color_manual(values = wesanderson::wes_palette("GrandBudapest1", n = 2))p_sw_iptw <- data %>% group_by(qsmk) %>% ggplot(aes(x = sw_iptw, color = qsmk, fill = qsmk)) + geom_histogram(bins = 50) + theme_minimal() + scale_fill_manual(values = wesanderson::wes_palette("GrandBudapest1", n = 2)) + scale_color_manual(values = wesanderson::wes_palette("GrandBudapest1", n = 2)) + geom_vline(xintercept = 1, color = "grey")# expected mean=2summary(data$iptw)## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 1.054 1.230 1.373 1.996 1.990 16.700p_iptw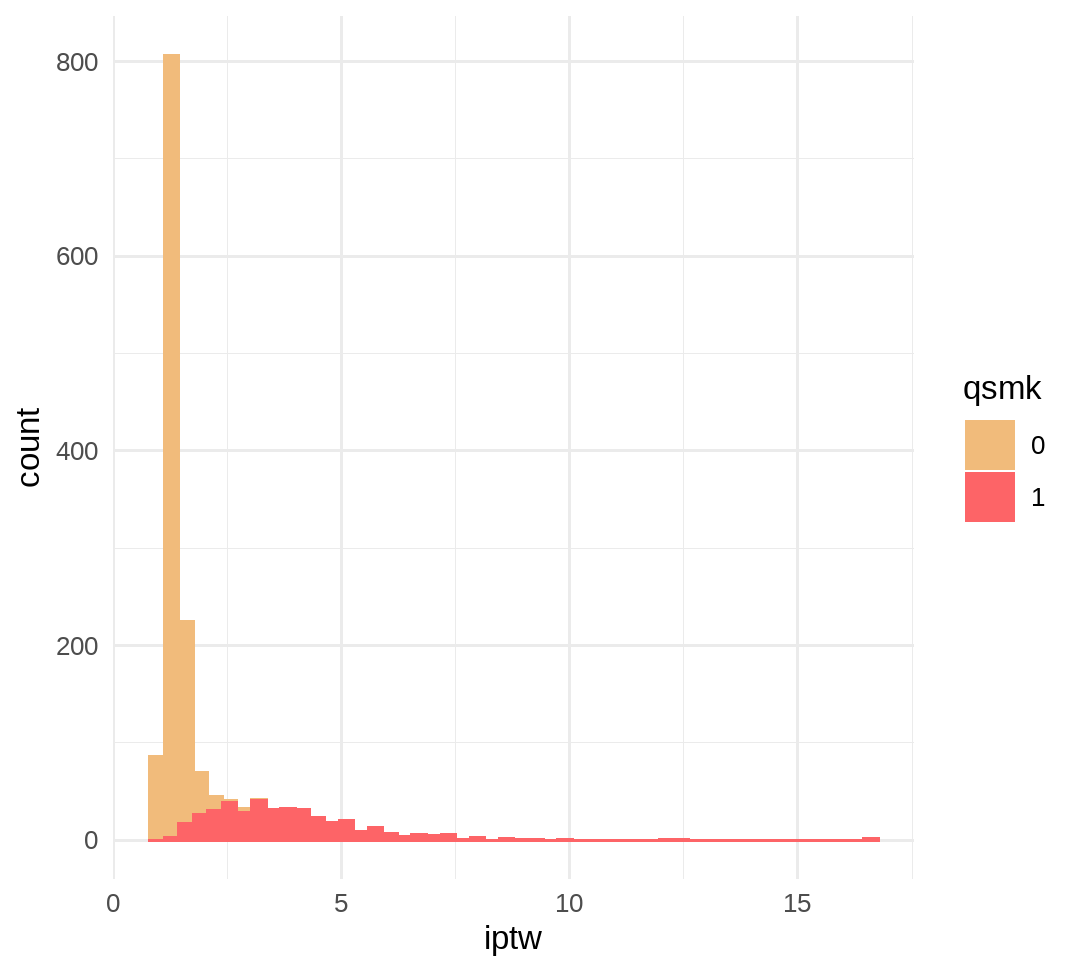
# expected mean=1summary(data$sw_iptw)## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.3312 0.8665 0.9503 0.9988 1.0793 4.2977p_sw_iptw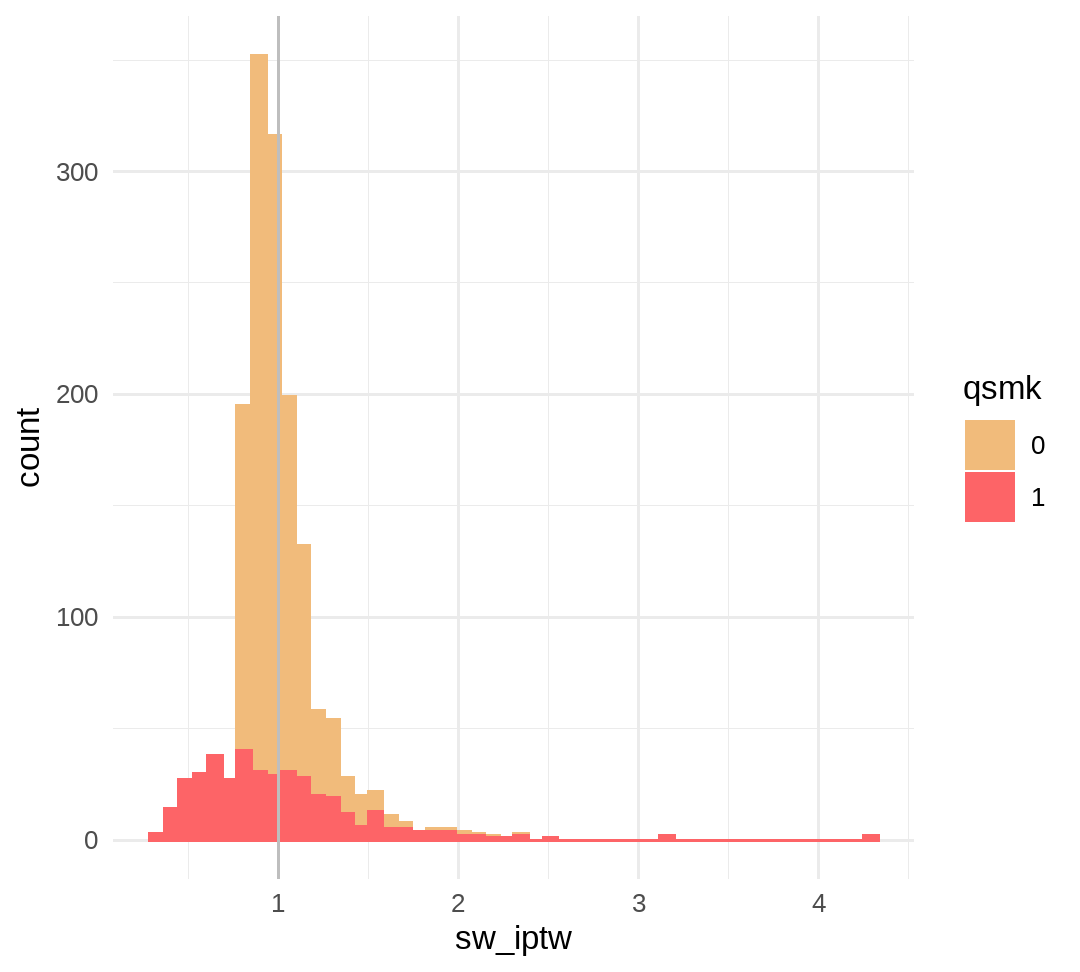
# 95% CIs are incorrectglm(data = data, formula = wt82_71~qsmk, family = gaussian(), weights = iptw) %>% broom::tidy(., conf.int = T) %>% select(term, conf.low, estimate, conf.high)## # A tibble: 2 x 4## term conf.low estimate conf.high## <chr> <dbl> <dbl> <dbl>## 1 (Intercept) 1.22 1.78 2.34## 2 qsmk1 2.64 3.44 4.24glm(data = data, formula = wt82_71~qsmk, family = gaussian(), weights = sw_iptw) %>% broom::tidy(., conf.int = T) %>% select(term, conf.low, estimate, conf.high)## # A tibble: 2 x 4## term conf.low estimate conf.high## <chr> <dbl> <dbl> <dbl>## 1 (Intercept) 1.33 1.78 2.23## 2 qsmk1 2.56 3.44 4.32library(tidymodels)set.seed(972188635)boots <- bootstraps(data, times = 1e3, apparent = FALSE)iptw_model_sw <- function(data) { glm(formula = wt82_71 ~ qsmk, family = gaussian(), weight = sw_iptw, data = data)}boot_models <- boots %>% mutate( model = map(.x = splits, ~iptw_model_sw(data = .x)), coef_info = map(model, ~broom::tidy(.x)))int_pctl(boot_models, coef_info) # M. Hernan: 3.4 (2.4-4.5)## # A tibble: 2 x 6## term .lower .estimate .upper .alpha .method ## <chr> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 (Intercept) 1.32 1.78 2.21 0.05 percentile## 2 qsmk1 2.42 3.44 4.48 0.05 percentileint_pctl(.data = boot_models_unst, statistics = coef_info)## # A tibble: 2 x 6## term .lower .estimate .upper .alpha .method ## <chr> <dbl> <dbl> <dbl> <dbl> <chr> ## 1 (Intercept) 1.32 1.78 2.21 0.05 percentile## 2 qsmk1 2.42 3.44 4.48 0.05 percentile